

![]() Само собой разумеется и во всех книгах проговаривают, что для нахождения элемента лучше всего и быстрее использовать локаторы id и name и, что характерно, основные примеры по использованию локаторов и по работе Selenium показывают именно с ними. Но в реальной жизни часто бывает так, что id элементов формируется динамически, а потому все привязки к нему бесполезны, class может иметь десятки представителей на странице, а name может отсутствовать. Как вы уже догадываетесь в этом случае нужно применять локаторы xpath и css. В данной статье я не собираюсь говорить о каком то превосходстве над css или сравнивать быстродействие, я лишь расскажу почему я использую именно xpath и как это нужно делать. Букв будет много, так как в свое время мне пришлось достаточно порыться в интернет, чтобы получить нужную мне информацию, я выкладываю все самое полезное, в надежде, что кому это поможет в использовании xpath-локаторов. Важно, что у тебя, мой читатель должно быть хоть небольшой представление о xpath, если его нет, то можешь скачать длинный мануал тут.
Само собой разумеется и во всех книгах проговаривают, что для нахождения элемента лучше всего и быстрее использовать локаторы id и name и, что характерно, основные примеры по использованию локаторов и по работе Selenium показывают именно с ними. Но в реальной жизни часто бывает так, что id элементов формируется динамически, а потому все привязки к нему бесполезны, class может иметь десятки представителей на странице, а name может отсутствовать. Как вы уже догадываетесь в этом случае нужно применять локаторы xpath и css. В данной статье я не собираюсь говорить о каком то превосходстве над css или сравнивать быстродействие, я лишь расскажу почему я использую именно xpath и как это нужно делать. Букв будет много, так как в свое время мне пришлось достаточно порыться в интернет, чтобы получить нужную мне информацию, я выкладываю все самое полезное, в надежде, что кому это поможет в использовании xpath-локаторов. Важно, что у тебя, мой читатель должно быть хоть небольшой представление о xpath, если его нет, то можешь скачать длинный мануал тут.
Сначала о том, почему новички (и не только) не любят xpath:
- Со времен далекой, далекой Галактики, существует миф о том, что xpath во много раз медленнее css, что на данный момент времени не является правдой. Не знаю как обстояло дело раньше, но в наши дни я лично написал несколько тестов с использованием xpath и css и сравнивая их могу сказать, что никакого значительного преимущества нет, а порой даже xpath работает быстрее. Не собираюсь вступать в длительные баталии по поводу скорости, просто разница в несколько миллисекунд нельзя считать значительной, особенно при общей длительности УИ-тестов.
- Xpath неверно используют, во многом из-за того, что стандартные панели разработчика и плагины выдергивают xpath из страницы в совершенно непотребном виде, который неудобен и нечитаем. Потому у многих сложилось мнение, что xpath это тяжеловесная и непонятная ерунда.
- Нет или по меньшей мере мне не попался какой-нибудь вменяемый мануал по xpath, в основном предлагают ссылки на pdf файл где локаторы приведены всей кучей вместе с css, этакая выжимка, в которой я уверен мало кто разбирается просто из-за обилия информации.
А теперь о том, как обстоят дела на самом деле и в чем преимущества xpath, если его правильно использовать:
— он не уступает (или незначительно уступает) в скорости css
— он понятен и легко читаем, по нему можно понять о каком элементе идет речь
— он похож на язык программирования и его удобно использовать
— можно добраться до самых запрятанных элементов страницы, благодаря выстроенным цепочкам отношений
 Итак, несколько правил использования xpath:
Итак, несколько правил использования xpath:
- Никогда не используй плагины или копирование xpath из кода страницы средствами браузера или веб-разработчика. Вот например как показывает одну ссылку плагин к Файрфокс: //header/div/ul/li[2]/a . Разве из этой ссылки понятно, о каком элементе речь, что мы ищем? Ведь порой бывает, что взглянув на локатор в коде или в тексте исключения мы должны понять о каком элементе речь. Как это можно понять из такой строки? Я уже не говорю о том, что любой код, основанный на таких локаторах упадет при любом дуновении ветерка. Каждый раз, когда ты пишешь локатор подобный //div[1]/div[2]/ul/li (продолжать можно долго) в мире умирает что-то хорошее!!! Это, если хотите, говнокод тестировщика, который нужно выжигать каленым железом.
- Старайся написать xpath как можно короче и понятнее, используй его возможности и схожесть с языком программирования, чтобы и через месяц ты сам мог понять о каком элементе речь и что нужно поправить в случае изменения верстки
- Xpath’у время и место! Если есть возможность использовать id, name или попросить разработчиков внести в код id то сделай это!
- Вместо длинной цепочки слешей, как указано выше, используй отношения элементов: предок, потомок, сестринский элемент
- Можно и нужно использовать логические операции and, not , or
- Нормальный xpath всегда начинается с // и не использует фильтры с номером элемента в стиле [2] (например //div[2])
Переходим к делу и практике, тот xpath, что указан выше (//header/div/ul/li[2]/a) на самом деле можно указать в виде //a[text()=’Pricing’]. Согласись, что есть разница и в длине текста и в понимании его, ведь тут видно по тегу, что это ссылка и ее текст –Pricing. То есть ты можешь и сам найти этот элемент на странице визуально и в случае исключения с таким локатором сразу знаешь, что и где искать!
Теперь о тех командах, которые тебе реально пригодятся для написания грамотных и удобных локаторов:
- text() – возвращает текст, содержащийся в элементе. Данную команду незаслуженно забывают и зря, ведь если ты посмотришь на любое веб-приложение, то ты там увидишь кнопки и ссылки, а на кнопках и в ссылках текст. И если id и class у них может меняться, то уверяю, текст на кнопке чаще всего остается тем же, а значит порой правки верстки никак не затрагивают твои локаторы, основанные на тексте! Не стесняйся применять локаторы основанные на тексте! Пример:

Как видим id явно сгенерирован и привязаться к нему нельзя, класс тоже не внушает доверия, кроме того Selenium не разрешает использовать сложносоставные имена в локаторе className, но тут есть текст, который решает проблему: //a[text()=’Contact us’]
- contains(параметр, искомое) –возвращает элемент если он содержит искомое, знакомая команда не так ли? Ты ее видишь постоянно в языке программирования. Очень удобно использовать в связке с text() если составляем сложный локатор и не знаем точно всего текста, например: //div[@class=’buttons’ and contains(text(),’Save’)] – как видишь, это некоторый элемент, который относится к кнопкам и на нем есть текст Save. Представь, что в твоем тестируемом веб-приложении есть несколько страниц, на которых есть кнопка сохранения, но с разными текстами –сохранить файл, сохранить диаграмму, сохранить отчет и так далее. Тебе не придется писать локаторы для них всех, хватит одного для всех кнопок сохранения и он описан выше. Обрати внимание на использовании в фильтре сразу двух условий!
Кроме того, очень полезная возможность – это искать элемент по одному из слов в названии класса.Пример:
Все решается вот так: //div[contains(@class,’intercomBtn’)] , то есть мы ищем элемент, у которого в классе есть какое-то уникальное сочетание слов. Данная возможность contains очень помогает в самых разных ситуациях! Обрати внимание, что параметр и искомое идут через запятую, нельзя писать contains(text()=’smth’)
- starts-with(параметр, искомое) –все аналогично contains, только эта команда возвращает элементы начинающиеся с искомого. Если возвращаться к примеру с кнопками сохранения, то локатор можно переписать вот так //div[@class=’buttons’ and starts-with(text(),’Save’)] у нас ничего не упадет, так как слово save обычно первое на кнопке и значит локатор опять же будет работать для всех кнопок сохранения. В общем это более узкая форма contains
Теперь пойдут команды отношения элементов (предок, родитель, ребенок, потомок, сестринский элемент), которые позволяют очень гибко найти практически любой элемент на странице при грамотном применении.
Формат использования //начальный элемент/отношение::тег(фильтр) конечного элемента. Обрати внимание на два двоеточия после отношения и не забывай после двоеточий указать тег, а лучше и фильтр искомого элемента, так как потомков может быть и много, а нам нужен какой-то конкретный.
- sibling – возвращает сестринский элемент, попросту говоря элемент, который расположен на том же уровне что и начальный –не потомок и не предок. Бывают двух типов preceding-sibling -сестринский элемент, который расположен до (выше) указанного и following-sibling – сестринский элемент, расположенный после (ниже) указанного. Пример:

Нам нужно ввести текст в input, но как видишь тут имеется ряд проблем – id динамический, классов и сгенеренных id со словом input на странице много, привязаться вроде не к чему. Но тут есть элемент с текстом, который уникален для страницы, вот к нему и прицепимся:
//div[text()=’Тема’]/preceding-sibling::input — мы сначала находим уникальный элемент с текстом, а потом от него ищем предшествующий сестринский элемент, делая фильтр-уточнение, что ищем именно input. Еще пример:
Нам нужно кликнуть кнопку, на которой нет текста, только иконка, но как видишь у нее все те же проблемы с id плюс есть куча одноименных классов. Нас спасает то, что у предшествующего элемента есть уникальное название класса, вот от него и будем плясать: //div[contains(@class,’listViewMoreActionsButton’)]/following-sibling::div – находим элемент у которого есть уникальное слово в названии класса и от него уже ищем следующий сестринский элемент, с тегом div. Учитывай, что даже если сестринских последующих элементов с тегом div будет много вернется только самый первый!
- parent и child, соответственно родитель и наследник(ребенок), обрати внимание что речь идет о непосредственном прямом родителе или наследнике, а не о предке или потомке. Если возвращаться к примеру
То представим, что нам нужен непосредственно элемент с id=__vz4019, для всех на данной картинке он является родителем (parent) и поэтому его можно вытянуть через любой из них, например //div[text()=’Тема’]/parent::div
![]() Кстати, обращение к родительскому элементу, можно заменить двумя точками и без тега, вот так //div[text()=’Тема’]/..
Кстати, обращение к родительскому элементу, можно заменить двумя точками и без тега, вот так //div[text()=’Тема’]/..
Так как все элементы в примере — дети, то можно любого из них найти от родителя вот так:
//div[contains(@class,’has-floating’)]/child::input – находим родителя, а от него ищем ребенка с тегом input.
- descendant – потомок, но отличие от child это может быть потомок любой вложенности, так сказать пра-пра-внук в том числе, а не только сын, потому важно не путать с непосредственным наследником! Пример:
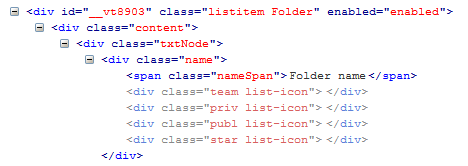
Нам нужна папка именно с определенным именем, но верстка организована так, что сам текст не содержится именно в элементе класса папка, поэтому нам надо найти сначала класс, а потом отфильтровать ту, у которой в потомках есть нужный текст:
//div[@class=’listitem Folder’]/descendant::span[text()=’Folder name’] –сначала находим класс папки, потом среди его потомков ищем тег span и нужный нам текст. Вы можете спросить –а почему просто по тексту не искать? Дело в том, что элементов с таким текстом на странице может быть больше одного, а нам нужна именно папка.
![]() Кстати вместо descendant можно использовать двойной слеш // это означает -любой вложенный элемент. Пример выше превращается в
Кстати вместо descendant можно использовать двойной слеш // это означает -любой вложенный элемент. Пример выше превращается в
//div[@class=’listitem Folder’]//span[text()=’Folder name’]
- ancestor – предок, опять же отличающийся от parent тем, что может быть любой удаленности, то есть прадедушкой. Если возвращаться к предыдущему примеру, то найти элемент папки по тексту можно так //span[text()=’Folder name’]/ancestor:: div[@class=’listitem Folder’]
Важно понимать, что можно, но крайне нежелательно использовать в одном локаторе несколько отношений, например:
//div[@class=’One]/child::div[@class=’Two’]/descendant::input[@class=’Three]. Такой локатор работать будет, но он уже сложно читается и скорее всего есть возможность подобрать другой, не нужно использовать такое без необходимости, помним правило номер 2. Совсем недопустимо использовать в одном локаторе обратные отношения то есть сначала искать потомка, потом его предка или наоборот.
Это все команды и отношения, которые вам пригодятся при написании локаторов! Да, есть еще и другие, вы можете с ними ознакомиться в мануале, прикрепленном в начале статьи, однако я их практически не использовал, а указанных в статье хватает мне и по сей день.
Итак, применяйте указанные команды, ищите правильные элементы, соблюдайте вышеозначенные правила и у вас не будет проблем с написанием грамотных локаторов, которые легко понять, прочесть, исправить. А главное вы поймете, что xpath очень удобен для написания локаторов к любым элементам.


Очень крутая статья! Реально спасибо
НравитсяНравится 1 человек
И если id и class у них может меняться, то уверяю, текст на кнопке чаще всего остается тем же, а значит порой правки верстки никак не затрагивают твои локаторы, основанные на тексте!
>>>
и если будут добавлять интернационализацию — то придется переписать каждый локатор обратно на id/class
НравитсяНравится
в жизни тестировщика вообще много если, если завтра захотят перписать всю верстку, то придется все локаторы менять. Интернационализация вдруг не возникает, или сразу есть хотя бы ru-eng или сразу только 1 язык, по крайней мере мне всегда так попадалось
НравитсяНравится
по поводу child и descendant — их чаще всего глупо использовать, потому что вот так на много читаемей, сравни:
//div[contains(@class,’has-floating’)]/child::input
и
//input[div[contains(@class,’has-floating’)]
или на любом уровне вложенности
//input[.//div[contains(@class,’has-floating’)]
НравитсяНравится
сравнил, не читаемей
НравитсяНравится
Очень толковая написано и по делу.
НравитсяНравится
Отличная статья, спасибо!
НравитсяНравится
Спасибо, очень долго искал объяснение following-sibling и preceding-sibling. Отличная статья!!!
НравитсяНравится
Спасибо огромное за статью! Разобралась наконец с xpath !!!
НравитсяНравится
Отличная статья, большое спасибо!
НравитсяНравится
Благодарю за статью! Пока освоил не всё, но буду ещё заглядывать в неё.
НравитсяНравится
Спасибо огромное за статью!!! Наконец то смогла написать Xpath привязаный к тексту другого элемента!
НравитсяНравится
Цитата «Это, если хотите, говнокод тестировщика, который нужно выжигать каленым железом.» 😂 👍 Классная статья! Спасибо!)
НравитсяНравится
Жаль я эту статью раньше не увидел. Спасибо
НравитсяНравится
ОЧЕНЬ КРУТО(ИНФОРМАТИВНО) СОСТАВЛЕННАЯ СТАТЬЯ! СПАСИБО БОЛЬШОЕ!) КАЙФАНУЛ.
НравитсяНравится